Java/Kotlinにおける非同期プログラミング
社内向けに書いた文章を一部編集してブログにも公開しています。
目的
- Java/Kotlinにおける非同期プログラミングの話について書きます。
- わかりやすさ優先で書くので、正確には正しくない表現がされていないことがあるかもしれません。ご容赦ください。
- なぜ非同期なのか?どういった歴史があったのか?いまはどうなのか? ーーといったことがこの記事を読めばわかると思います。
- あまり網羅的に書かれた記事等を見つけれなかったので、自分で書きます。
用語整理
ブロッキング/ノンブロッキング/非同期という用語は、コンテキストによって意味が変わってきます。このへんは技術記事/ブログでも混合していて非常にややこしいので、一番最初に整理します。
この記事ではこれらの用語を以下のように使い分けます。
- blocking、同期
- ある関数/メソッド等を実行したときに、結果が返ってくるまで呼び出したスレッドをblockingする処理のことを意味します。
- non-blocking、非同期
- ある関数/メソッド等を実行したときに、スレッドをblockせずに結果をコールバック関数やPromise/Futureの類のようなもので得る処理のことを意味します。
- 結果がくるまでスレッドを止めて待機することもできます。(blocking/同期処理化することもできる)
ただし、IOに関するときは意味合いが変わってきます。
- blocking IO
- システムコールレベルでblockingなIOのこと。(アプリケーションの観点ではblocking処理)
- BIOと略すことがある。
- non-blocking IO (IO Multiplexing)
- select / poll / epoll / kqueue といったシステムコールを用いたnon-blockingなIOのこと。(アプリケーションの観点では、non-blocking/非同期処理)
- NIOと略すことがある
- asynchronous IO
- 別スレッド上でblocking IOを実行し、その結果をコールバックで得るIOのこと。(アプリケーションの観点では、non-blocking/非同期処理)
- AIOと略すことがある
例えば、非同期処理として有名なnode.js(libuv)は、network IOにはNIOを使っていて、ファイル周りのIOはAIOを使っています。
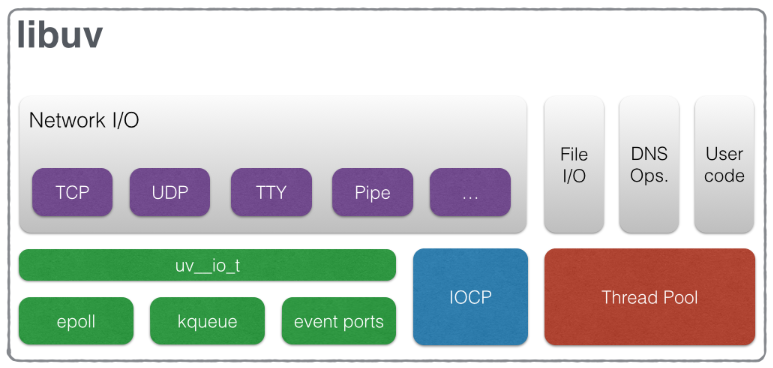
Javaにおいては、ライブラリによってマチマチです。
- blocking IO (スレッドを使ったasynchronous IOにも一部対応している)
- non-blocking IO
非同期プログラミングとは
この記事を見ているということは、非同期プログラミングについてすでに聞いたことがあるんだと思います。
一番身近なところでいうと、ブラウザ上で動くJavaScriptはシングルスレッドで動いています。そのため、JavaScriptの経験がある人ならば、比較的馴染みがあるはずです。 例えば、JavaScriptでは普通の言語であるようなスレッドをsleepする関数はなく、かわりにsetTimeoutという関数をコールバック関数と組み合わせて使います。シングルスレッドのJavaScriptでは、スレッドをブロックしてしまうとUIのレンダリング等も止まってしまうため、このような手法が用いられます。
window.setTimeout(() => window.alert("hello"), 2000);
コールバック関数を使っていくスタイルは コールバック地獄 という現象を引き起こし、その後JavaScriptにおいてはPromiseが導入され、更にその後、async/awaitという仕組みが登場しました。これにより、コールバックを使わずにsleepを実現させることができるようになりました。だいぶ書きやすくなり、良い時代になりました。
const sleep = msec => new Promise(resolve => setTimeout(resolve, msec));
await sleep(2000)
window.alert("hello")
一方、Javaで非同期プログラミングを行った経験がある人はあまりいないように思います。 Javaはマルチスレッド関連の標準ライブラリ(ExecutorService等) が充実しているため、自然とスレッドと同期型なプログラミングを組み合わせて使う機会が多いからです。
後述する理由で、Javaにおいても(もちろん、他の言語でも)非同期プログラミングの波がきています。 Javaの主流なフレームワークであるSpringも、Spring5(2017年10月)からWebFluxという仕組みが導入されました。 また、近年ではサーバーサイドにおいてBetter JavaとしてKotlinを使うことが多くなりましたが、Kotlin Corotines(suspend function) のおかげで非同期プログラミングへのハードルも下がってきており、プロダクション環境に非同期が求められるフレームワークを導入する機会も増えてきました。 実際に、私も業務で同時接続30万近くある 比較的大規模なチャットシステム をWebFluxを用いて実装しています。
そこで、初めてJava/Kotlinで非同期プログラミングを行う人向けにこの記事を書きました。要点をおさえて網羅的に書くことを目指しています。ところどころ気になったところは各自で深堀りしていただけると良いと思います。
なぜ非同期にするのか
ズバリ、少ないリソースで効率よく処理をすることが可能となるからです。
実際の例で提示したほうがわかりやすいでしょう。ちょっとしたEchoサーバーを例に說明します。
JDK1.0から存在する、もっとも基本的なjava.net.Socketを使って実装します。だいたい、以下のようになります。 InputStream/OutputStreamを利用したSocketのread&writeは、IOが完了するまでthread(今回だとmain thread)をblockする blockingな処理 となっています。
fun main() {
val serverSocket = ServerSocket(8080)
while (true) {
val socket = serverSocket.accept()
echo(socket)
}
}
private fun echo(socket: Socket) {
try {
socket.use {
val inputStream = socket.getInputStream()
val outputStream = socket.getOutputStream()
val bytes = ByteArray(8192)
var numOfReadBytes: Int
// このreadはblocking IO
while (inputStream.read(bytes).also { numOfReadBytes = it } >= 0) {
// このwriteはblocking IO
outputStream.write(bytes, 0, numOfReadBytes)
log.info("Echo: {}", String(bytes, 0, numOfReadBytes).trim())
}
outputStream.flush()
}
} catch (e: IOException) {
log.error("Failed to echo")
}
}
main threadがblockされているため、当然新規のクライアントからのリクエストをハンドリングすることができません。 (実際にtelnetしてみると、その様子が確認できます)
1クライアントしか捌くことのできないサーバーでは、まともなサービスを提供することはできません。
そこで、複数のクライアントからのリクエストをハンドリングできるように、以下のようにマルチスレッド化します。 200個のスレッドプールを使っているので、200 clientまで同時にハンドリングすることができます。
fun main() {
val executor = Executors.newFixedThreadPool(200)
val serverSocket = ServerSocket(8080)
while (true) {
val socket = serverSocket.accept()
executor.execute {
echo(socket)
}
}
}
private fun echo(socket: Socket) {
try {
socket.use {
val inputStream = socket.getInputStream()
val outputStream = socket.getOutputStream()
val bytes = ByteArray(8192)
var numOfReadBytes: Int
// このreadはblocking IO
while (inputStream.read(bytes).also { numOfReadBytes = it } >= 0) {
// このwriteはblocking IO
outputStream.write(bytes, 0, numOfReadBytes)
log.info("Echo: {}", String(bytes, 0, numOfReadBytes).trim())
}
outputStream.flush()
}
} catch (e: IOException) {
log.error("Failed to echo")
}
}
というわけで、スレッドの数が許す限りはスケールさせていくことができます。しかし、スレッドはリソースを多く使用しがちな仕組みです。
- メモリが必要
- デフォルトで1スレッドあたり最低でも1MB必要となります。(ref: -Xss)
- 1000個のスレッドを作ると、スレッドだけでも1GB必要となってしまいます。
- コンテキストスイッチの負荷が増える
- コンテキストスイッチにかかる時間は、CPUの立場からすると1時間くらいかかるといわれています。
- GCの負荷も増える
- GCの際に、スレッドを止める必要があるため。
実際に、スレッドを大量につくると割と簡単にOOMEが発生することが確認できます。(もちろん、heap sizeによりますが)
fun main() {
repeat(10_000) {
thread { // launch a lot of thread
Thread.sleep(5000L)
print(".")
}
}
}
このあたりの話は、俗にいうC10K問題(1999年)というものです。 1GHzのシングルCPU、2GBメモリ、1Gbpsネットワークの1つのサーバーのみで、どうすれば1万のクライアントに同時にFTPサービスを提供することができるだろうか?という問題提唱です。 2GBだとJavaのスレッドは2000個しか作れないので、上述したようにこの要件は満たすことができません。
これを解決するためにLinux等においてselect / poll / epoll / kqueueといったシステムコールが誕生し、non-blocking IO(& IO多重化)が世に普及しました。
これらの仕組みはめちゃくちゃざっくりというと、socket(file descriptor)が○○な状態になったら、OSがアプリケーションに通知して教えてくれる仕組みです。 準備ができてからread/write等をすることができるので、blockingすることなる読み書きすることができます。
このへんは後述するJavaコードを見たほうが、イメージつきやすいかもしれません。
また一方で、近年はマイクロサービスを採用することが増えています。しかし、マイクロサービスとスレッドプールを用いた同期的なプログラミングは相性が悪いです。
マイクロサービスのどこかのサービスで障害が発生し、timeout errorが多発するようになると、そのせいであっという間にスレッドプールが枯渇してしまい、本来正常であるはずの機能にまで影響が生じてしまいます。
ref: Armeria: A microservice framework well-suited everywhere
non-blocking IOにすることで、そういった問題も解決することができます。(が、これに関してはちゃんとサーキットブレーカーを入れたほうがいいでしょう)
NIO from JDK1.4 (2002年)
Javaにおいては、JDK1.4から登場したNIO(ややこしいことに、New IOの略)によって、non-blocking IOがサポートされました。
先程のEchoサーバーをNIOを使って実装してみます。 以下のようになります。コードの詳細は割愛します。ひとまず、以下のポイントだけおさえておけばいいです。
- non-blockingになったことで、main threadのみで複数のクライアントからのリクエストを処理することができるようになった。
- event loopという概念
- Selectorに対して、アプリケーションが関心のあるイベントを登録(register)します。
- 例えば、Socketが読み取り可能になったというイベント
- Selectorは、OSの種類に応じて最も性能のいいシステムコール(select / poll / epoll / kqueue)を利用してくれます。Linuxならepollが使われる。
- mainスレッド上のwhile loopで、登録したイベントが発生しているかどうかを常時チェックします。これをevent loopと呼びます。
- イベントがある場合は、それに相当する処理を実行します。
- Selectorに対して、アプリケーションが関心のあるイベントを登録(register)します。
fun main() {
val selector = Selector.open()
ServerSocketChannel.open().apply {
configureBlocking(false);
socket().bind(InetSocketAddress(8080));
register(selector, SelectionKey.OP_ACCEPT);
}
// いわゆる event loop
while (selector.select() > 0) {
val iterator = selector.selectedKeys().iterator()
while (iterator.hasNext()) {
val key = iterator.next()
iterator.remove()
if (key.isAcceptable) {
accept(key.channel() as ServerSocketChannel, key.selector())
} else if (key.isReadable) {
read(key.channel() as SocketChannel, key.selector())
} else if (key.isWritable) {
write(key.channel() as SocketChannel, key.selector(), key.attachment() as ByteBuffer)
}
}
}
}
private fun accept(serverSocketChannel: ServerSocketChannel, selector: Selector) {
val channel = serverSocketChannel.accept()
channel.configureBlocking(false)
channel.register(selector, SelectionKey.OP_READ)
}
fun read(socketChannel: SocketChannel, selector: Selector) {
val byteBuffer = ByteBuffer.allocate(1024)
if (socketChannel.read(byteBuffer) < 0) {
socketChannel.close()
return
}
byteBuffer.flip()
socketChannel.register(selector, SelectionKey.OP_WRITE, byteBuffer)
}
fun write(socketChannel: SocketChannel, selector: Selector, byteBuffer: ByteBuffer) {
val writeBytes = socketChannel.write(byteBuffer)
log.info("Echo: {}", String(byteBuffer.array(), 0, writeBytes).trim())
socketChannel.register(selector, SelectionKey.OP_READ)
}
telnetをしてみると確認できますが、main thread(event loop thread)のみで複数のリクエストをハンドリングできるようになりました。 一般的に、event loop threadはCPUコアの数ぶん用意されます。
Nettyの登場 (2007年頃)
NIO(JDK1.4)の登場により、Javaでもnon-blocking IOが使えるようになりましたが、先程見たようにだいぶlow levelなAPIなのでそのまま使うにはいささか不便 & 難しいです。
そこで、Nettyというライブラリが登場しました。(正確には、その前にApache MIMAなどもありましたが) 名前は聞いたことがある人も多いのではないかと思います。
Nettyはtrustinによって開発されました。彼はその後LINEにてNettyをベースとしてArmeriaの開発をしました。
Nettyの登場以後、Javaにおけるnon-blocking IOではNettyがデファクトとして使われるようになっていきました。 メジャーどこでいうと、以下のようなフレームワーク/ライブラリでもNettyが使われています。
- Spring WebFlux
- Armeria
- Play Framework (MIMA → Netty → Akka HTTPと変遷している)
- Vert.x
- Finagle (twitter)
- lettuce
- ... etc
Nettyを使って、先程のEchoサーバーを書き直してみましょう。だいぶ簡潔に書けるようになったことがわかると思います。開発者がSelectorを使ったevent loop等を実装しなくて済むようになりました。
fun main() {
ServerBootstrap().apply {
group(NioEventLoopGroup())
channel(NioServerSocketChannel::class.java)
childHandler(object : ChannelInitializer<SocketChannel>() {
override fun initChannel(channel: SocketChannel) {
// コールバック(EchoHandler)を使ってnon-blockingで記述する
channel.pipeline().addLast(EchoHandler())
}
})
bind(8080)
}
}
@ChannelHandler.Sharable
private class EchoHandler : ChannelInboundHandlerAdapter() {
override fun channelRead(ctx: ChannelHandlerContext, msg: Any?) {
log.info("Echo: {}", (msg as ByteBuf).toString(StandardCharsets.UTF_8).trim())
ctx.write(msg)
}
override fun channelReadComplete(ctx: ChannelHandlerContext) {
ctx.flush()
}
override fun exceptionCaught(ctx: ChannelHandlerContext, cause: Throwable) {
log.error("Unexpected exception. ctx={}", ctx, cause)
ctx.close()
}
}
(おまけ) NIO.2 from JDK1.7 (2011年)
JDK1.7にて、NIO.2が追加されました。
これにより、Network IOとFile IOにおいて、asynchronous IOを使うことができるようになりました。(AsynchronousSocketChannel/AsynchronousServerSocketChannel, AsynchronousFileChannel)
ただし、Network IOにおいてはNIOを使ったほうが性能がいいので、AsynchronousSocketChannel/AsynchronousServerSocketChannelに関してはあまり広く使われていないように思います。
Nettyも一時期AIOのサポートをしていましたが、途中でサポートを打ち切ったようです。
https://github.com/netty/netty/issues/2515
一方、FileのAIO(AsynchronousFileChannel)に関しては使われているように思います。例えば、
- Spring WebFlux: DataBufferUtils
- Vert.x: AsyncFile
- ...
JavaのWebフレームワークのIOの変遷
blocking IOをベースとしたServlet(Tomcat)が古来から現在まで、主に使われています。
2010年中盤頃から、non-blocking IOをベースとした後発のWebフレームワークやコンテナファーストを売りにしたWebフレームワークがポツポツと登場してきました。
blocking IO based
blocking IO basedなWebフレームワークは、だいたいはServlet(Tomcat)を使って実装されています。なので、Servlet(Tomcat)の変遷を紹介します。
Servlet(Tomcat)
Spring MVCはServlet(Tomcat)を使っているので、Spring MVCの変遷だと認識しても問題はありません。以下のように、様々な問題をちょっとづつ改善されてきました。
※ 以下の図はこちらの記事より引用させてもらっています。
Java ブロッキングとかノンブロッキングを理解したい
BIOコネクタ (Tomcat9以降、削除された)
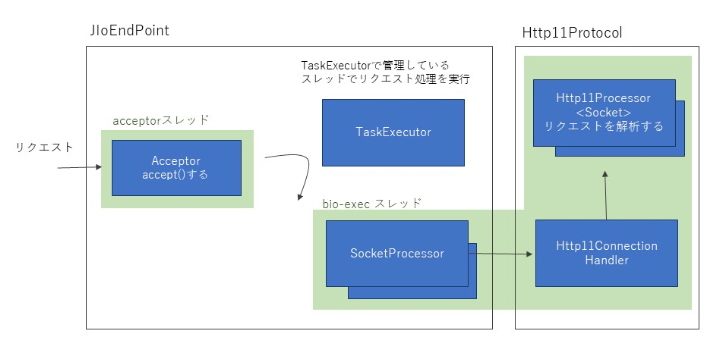
- 特徴
- Socket#accept()以降、スレッドがずっと占有される
- HTTP Keep-aliveの場合、スレッドはkeep-aliveが続く限りずっと占有され続ける
NIOコネクタの登場
現在のデフォルトの挙動。
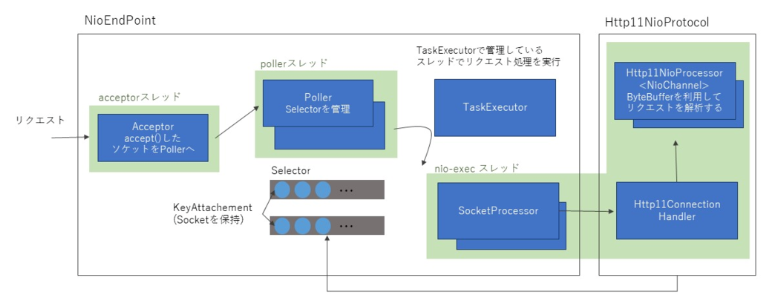
- 特徴
- HTTP Keep-aliveのためにスレッドが占有されなくなった
- ただし、HttpServlet#service以降の処理(Spring MVCでいうところのコントローラー以降)はリクエストごとにWorkerスレッドを専有します。なので、対抗サーバーが障害で応答しなくなったりするとWorkerスレッドプールが枯渇して障害になったりします。
Servlet3.0 Async Servlet Support
処理中にworkerスレッドを解放し、別のスレッドを使って実行することができる仕組み。
Springのコントローラーの返り値をCallableやDeferredResult, ListenableFuture, CompletableFutureにすることで使用することができる。
この記事がとても詳しいです。
Spring MVC(+Spring Boot)上での非同期リクエストを理解する -前編-
Spring MVC(+Spring Boot)上での非同期リクエストを理解する -後編(HTTP Streaming)-
- 特徴
- けっきょく他のスレッドを使うだけではある
- だったらtomcatのリクエストスレッドを多めに用意しておけばよくない...? が、例えばファイルアップロードAPIだけ別スレッドプールで管理したいというニーズはあるかもしれない。
- HttpServletRequest#getInputStream() と HttpServletResponse#getOutputStream()による読み取り/書き込みは依然としてblockingな処理
- なので、request/response sizeがでかいとき、ネットワークが低速なときは長時間スレッドがblockされうるというリスクは改善されないまま。(InputStream/OutputStreamを使う以上、改善は無理)
- けっきょく他のスレッドを使うだけではある
Servlet 3.1 Non-Blocking I/O
Servletが真にnon-blocking IOに対応したが、これについては知らなくていい。既存のServletのいくつかのAPIを使用することができなくなるため、Spring MVCとして採用されることはありませんでした。 正確にいうと例えばSpring WebFluxではオプションとしてServlet 3.1を使うことができますが、Spring WebFluxはデフォルトでNettyを使用するので、あえてServlet 3.1を選択する必要がありません。
non-blocking IO based
Springがnon-blocking対応に出遅れたこともあって、わりと色々な種類のWebフレームワークがポツポツと登場しました。だいたいNettyをもとに実装されています。
これらのフレームワークはevent loop thread上で実行されるので、非同期プログラミングでビジネスロジックを実装する必要があります。
Vert.x (2013年)
あまり日本で採用されている話を聞かないので省略。
Armeria (2015年)
(version1系がでたのは2020年)
LINEが作っているnon-blockingなWebフレームワークです。microserviceを構築するうえで必要な機能(Resilience, Observability, Service-Discovery)が漏れなく搭載されているので、便利です。
Spring WebFlux (2017年10月)
Spring5から登場したnon-blockingなWebフレームワークです。
Spring MVCとは互換性はありません。そのため、使い方は新規に覚える必要があります。が、わりと似ているのでそんなに困ることはありません。
Micronaut, Quarkus(RedHat), Helidon(Oracle)
最近よくみかける3つのフレームワークたち。個人の感想なので完全にスルーしていいですが、この中だったらQuarkusが一番良さそうかな。 なお、MicronautとQuarkusに関しては、blocking basedな従来の方法もサポートされています。登場と同時にnon-blocking basedな実装があったので、こちらに分類させてもらいました。
非同期/non-blocking は銀の弾丸なのか?
「NIO from JDK1.4 (2002年)」のセクションで見たとおり、1つのスレッド(= 少ないリソース)で複数のリクエストを捌くことができるようになりました。
これだけ見るとデメリットの一切ない、銀の弾丸のようなものに思えます。
しかし注意点として、non-blocking IOをベースとしたWebフレームワークを使用する場合はblockingな処理をしてはいけません。 前述したevent loop threadをblockさせてしまうため、途端に性能がでなくなってしまいます。 そのため、ブラウザにおけるJavaScriptのようにCallbackやPromiseを使って非同期にビジネスロジックを記述する必要があります。
これがなかなか厄介です。というのも、サーバーサイドエンジニアは比較的非同期プログラミングに不慣れな人が多いです。また、普通に考えて人間からしたら上から下に同期的に実行されていくプログラミングのほうが読み書きしやすいです。 Javaにおいては後述する様々な非同期なAPIを使ってプログラミングを行う必要性が生じるわけですが、これらを覚えるラーニングコストが問題となります。
一方でKotlin coroutinesのように、言語の機能としてこれらを改善する仕組みもあります。coroutinesを使うことで、こういったコストはある程度解消されます。
また、非同期/non-blocking特有のトラブルに遭遇することもあるでしょう。この記事で歴史/変遷の說明をしたのは、こういった背景がわかっていないと解決することが難しいことがあるからです。
なので、プロダクトの性質/チームメンバーの習熟度を鑑みた上で採用の有無を決定するといいと私は思います。
典型的には、Gateway/Proxyサーバー, 認証サーバー、WebSocket/SSE/Long Pollingのようなサーバーには特にnon-blockingが向いています。こういった機能を実装するときは、勉強して挑戦してみるのはいいかと思います。
非同期API/手法の紹介
いくつか紹介しますが、現時点での主流は以下の通りです。この3つを把握しておけばいいでしょう。だいたいのライブラリはinterfaceにこれらを使っています。例えばlettuceは、これら3つのすべてに対応しています。
- CompletableFuture
- Reactive Streams (Reactor)
- Kotlin Coroutines (suspend function)
特に近年においては、JavaではReactive Streams、KotlinではCoroutines (suspend function)が使われることが多いです。
コールバック
このスタイルはあまり見かけなくはなりましたが、一応紹介します。コールバックを使うパターンです。
昔のJavaScriptっぽくて、あんま良いものではないですね...。まさにコールバック地獄といった感じです。例外ハンドリングもコールバックのたびに記述する必要があって、少し手間ですね。
fun getFavoriteItems(request: HttpRequest, response: HttpResponse) {
val token = request.header("x-some-token")
getLoggedInUser(token, object : Handler<User> {
override fun onCompleted(result: User) {
getFavoriteItems(result.userId, object : Handler<List<Item>> {
override fun onCompleted(result: List<Item>) {
response.ok(result)
}
override fun onFailed(e: Exception) {
response.status(HttpStatus.INTERNAL_SERVER_ERROR, "failed to get favotite items")
}
})
}
override fun onFailed(e: Exception) {
response.status(HttpStatus.UNAUTHORIZED, "failed to authenticate")
}
})
}
interface Handler<T> {
fun onCompleted(result: T)
fun onFailed(e: Exception)
}
// コールバックを渡す
fun getLoggedInUser(token: String, handler: Handler<User>) {
// 省略
}
// コールバックを渡す
fun getFavoriteItems(userId: String, handler: Handler<List<Item>>) {
// 省略
}
ラムダを使って、このように書くケースもあります。若干記述量は減りますが...、特に体験は変わりません。
fun getFavoriteItems(request: HttpRequest, response: HttpResponse) {
val token = request.header("x-some-token")
getLoggedInUser(
token,
{ user ->
getFavoriteItems(
user.userId,
{ items -> response.ok(items) },
{ e -> response.status(HttpStatus.INTERNAL_SERVER_ERROR, "failed to get favotite items") }
)
},
{ e -> response.status(HttpStatus.UNAUTHORIZED, "failed to authenticate") }
)
}
// コールバックを渡す
fun getLoggedInUser(token: String, onCompleted: (User) -> Unit, onFailed: (Exception) -> Unit) {
// 省略
}
// コールバックを渡す
fun getFavoriteItems(userId: String, onCompleted: (List<Item>) -> Unit, onFailed: (Exception) -> Unit) {
// 省略
}
また、同一スレッド上で結果を同期的に取得することができないので、同期的なプログラミングをしたい時だと困ってしまいます。
例えば、KafkaのProducer#send()はこのようにコールバックを渡すことができます。
https://github.com/apache/kafka/blob/2.1.0/clients/src/main/java/org/apache/kafka/clients/producer/Producer.java#L73
Future from JDK1.7
次に、JDK1.7から追加されたFutureです。
非同期処理の結果を保持するクラスなのですが、その結果を取得するにはget()というblockingなメソッドを呼び出すしかありません。(結果が取得できるまでスレッドをblockするメソッドです。) 非同期プログラミングをするときには、端的にいってあまり役に立つことがない代物です。一方、同期的に書くときは結果を待つことができるという点で役に立ちますが...。
非同期プログラミングでFutureに遭遇してしまったときは、残念ながら後述するCompletableFuture/Reactor等に変換する必要があります。
https://stackoverflow.com/questions/23301598/transform-java-future-into-a-completablefuture
例えば、KafkaのProducer#send()はFutureを返します。(ただ、このメソッドに関してはコールバックを渡すこともできるので困ることはありません) https://github.com/apache/kafka/blob/2.1.0/clients/src/main/java/org/apache/kafka/clients/producer/Producer.java#L73
オレオレFuture
JDK1.7にて追加されたFutureは、前述したように欠点があるものでした。 そこで、Futureを改良したオレオレFutureを各種ライブラリが作り出しました。 オレオレFutureが跋扈する戦乱の世の始まりです。
もっとも有名なのが、Guava(Google)のListenableFutureでしょうか。 その名の通り、Listener(コールバック)を追加することができるFutureです。このListenableFutureを使うと以下のように、書くことができます。 ただまあ...結局コールバックを使うだけなので対して書き味は変わりませんね...。 (Guava23で追加されたFluentFutureを使うと改善できますが、今回はあえて昔ながらの書き方をしています)
private val executor = Executors.newFixedThreadPool(10)
fun getFavoriteItems(request: HttpRequest, response: HttpResponse) {
val token = request.header("x-some-token")
Futures.addCallback(
getLoggedInUser(token),
object : FutureCallback<User> {
override fun onSuccess(result: User?) {
Futures.addCallback(
getFavoriteItems(result!!.userId),
object : FutureCallback<List<Item>> {
override fun onSuccess(result: List<Item>?) {
response.ok(result!!)
}
override fun onFailure(t: Throwable) {
response.status(HttpStatus.INTERNAL_SERVER_ERROR, "failed to get favotite items")
}
},
executor
)
}
override fun onFailure(t: Throwable) {
response.status(HttpStatus.UNAUTHORIZED, "failed to authenticate")
}
},
executor
)
}
// ListenableFutureを返す
fun getLoggedInUser(token: String): ListenableFuture<User> {
// 省略
}
// ListenableFutureを返す
fun getFavoriteItems(userId: String): ListenableFuture<List<Item>> {
// 省略
}
とはいえListenableFutureを使うことで非同期に書くこともできるし、get()を呼び出すことでスレッドをblockして結果を取得することもできるようになりました。
参考までに、パッと思いついた他のライブラリによるオレオレFutureを紹介してみましょう。
- SpringのListenableFuture
- LettuceのRedisFuture
- ただ、現在は後述するCompletionStage互換になっている
- GCP SDKのApiFuture
- Async Http ClientのListenableFuture
- vert.xのFuture
https://github.com/spotify/futures-extra 等を使えば、後述のCompletableFutureに変換することができます。
CompletableFuture(CompletionStage) from JDK1.8 (2014年)
JDK1.8にてJDK標準としてCompletableFutureが導入されました。
今までのコード例をCompletableFutureを使ってかくと、次のようになります。 メソッドチェーンを使って書いていくといった感じで、JSのPromiseに近い感じで書けますね。 コールバックスタイルのときと違って、例外ハンドリングもまとめて一箇所で行うことができるのも良い点です。 Webフレームワークによっては、コントローラーの返り値がCompletableFutureになっていて、例外ハンドリングは別の仕組みで行うこともあります。
fun getFavoriteItems(request: HttpRequest, response: HttpResponse) {
val token = request.header("x-some-token")
getLoggedInUser(token)
.thenCompose { getFavoriteItems(it.userId) }
.whenComplete { result, throwable ->
if (throwable == null) {
response.ok(result)
} else {
when (throwable.cause) {
is AuthenticateException -> response.status(HttpStatus.UNAUTHORIZED, "failed to authenticate")
else -> response.status(HttpStatus.INTERNAL_SERVER_ERROR, "failed to get favorite items")
}
}
}
}
// CompletableFutureを返す
fun getLoggedInUser(token: String): CompletableFuture<User> {
// 省略
}
// CompletableFutureを返す
fun getFavoriteItems(userId: String): CompletableFuture<List<Item>> {
// 省略
}
また、get/joinを呼び出すことでthreadをblockして結果を得ることもできるので、従来の同期的なプログラミングにおいても使うことができます。 つまり、IO処理をするクラスはCompletableFutureを返すように設計しておけば、非同期/同期プログラミングの両方に使えるので便利です。
ただ、CompletableFutureに連なる一連のメソッドチェーン(thenCompose, ...etc)の中で、うっかりとblocking処理がnon-blockingなthread上で実行されないように注意してください。 その場合は、thenXXXAsync等のメソッドを使い、blockしても良いExecutor/スレッドプールを引数に渡してください。
初見だとthenXXX, whenXXX等メソッドが多くて混乱しますが、IDE上でjavadocを眺めながら書けばあまり困ることはないと思います。
CompletableFutureの作り方
基本的にはCompletableFutureに対応しているライブラリ側が作ってくれるので自分で書くケースは少ない、と思います。が、blockingな処理(e.g. JDBC)を非同期化する時は自分で作る必要があるので、簡単にですが紹介しておきます。
CompletableFuture.supplyAsyncメソッドに対して、blockingな処理と実行したいExecutor(スレッドプール)を渡してあげればいいです。
private val executor = Executors.newFixedThreadPool(10)
fun getLoggedInUser(token: String): CompletableFuture<User> {
return CompletableFuture.supplyAsync(
{ verifyToken(token) }, // blockingな処理
executor
)
}
ただしあくまでスレッドプールを使って非同期化するだけなので、non-blocking IOと比較するとあまり効率はよくありません。(前述したように)
すでに値がある場合は、CompletableFuture.completedFuture("hoge") 等で作ることもできます。
Reactive Streams (Reactor)
Reactive Streamsだけでこの記事と同量くらいの解説が書けてしまうくらいのコンテンツなので、今回はざっくりとした說明で済ませます。
Reactive Streamsは簡単にいうと、非同期にストリーム(連続する複数)なデータを取り扱うための手法/仕組みです。 今までは非同期に単一のデータを扱うことについて着眼していましたが、その対象がストリームなデータにまで広がったと認識してください。 ストリームなデータとは、わかりやすい例でいうとWebSocketとかRedis Subscribeとかのことです。実際に、これらを取り扱うときは後述するFluxが使われます。
仰々しい名称を名乗ってはいますが、いわゆるObserver Patternのようなものです。
Reactive Streams自体は手法/仕組み(要するにinterface)であって、それに沿って実装したライブラリを各社が提供しています。 サーバーサイドでいうとはSpring(Pivotal)を使う事が多いため、Pivotalが実装しているReactorを使用する機会が多いと思います。 (他の有名所でいうと、RxJava, Akka Streamsなど)
詳細については以下の記事を見てください。(個人的には、読むだけじゃなくて実際にコードを動かしてみたほうが理解しやすいと思います。)
- Java SE 9の非同期処理ライブラリ、新概念の「Reactive Streams」を学ぶ
- Let’s play Reactive Streams with Armeria vol.1
- Reactive Streams
- https://github.com/reactor/lite-rx-api-hands-on
非同期にストリームなデータを取り扱うための手法/仕組みといいましたが、もちろん、単一なデータを取り扱うこともできます。
Reactorにおいては、ストリームなデータはFlux
Monoに関しては、実質先程說明したCompletableFutureと使い方はそんなに変わりません。 今までのコード例をMonoを使って書くと、以下のようになります。 CompletableFutureのときのように、flatMap/map等のメソッドチェーンをつないでいくスタイルになります。
// Reactor対応しているWebフレームワークの場合は、コントローラーの返り値もMonoになっている
fun getFavoriteItems(request: HttpRequest): Mono<ResponseEntity<Any>> {
val token = request.header("x-some-token")
return getLoggedInUser(token)
.flatMap { getFavoriteItems(it.userId) }
.map { ResponseEntity.ok<Any>(it) }
.onErrorResume {
when (it) {
is AuthenticateException -> Mono.just(
ResponseEntity.status(HttpStatus.UNAUTHORIZED).body("failed to authenticate")
)
else -> Mono.just(
ResponseEntity.status(HttpStatus.INTERNAL_SERVER_ERROR).body("failed to get favorite items")
)
}
}
}
// Monoを返す
fun getLoggedInUser(token: String): Mono<User> {
// 省略
}
// Monoを返す
private fun getFavoriteItems(userId: String): Mono<List<Item>> {
// 省略
}
また、block()を呼び出すことでthreadをblockして結果を得ることもできるので、従来の同期的なプログラミングにおいても使うことができます。 つまり、IO処理をするクラスはMonoを返すように設計しておけば、非同期/同期プログラミングの両方に使えるので便利です。
ただし、Monoに連なる一連のメソッドチェーン(flatMap, Map, ...etc)の中で、うっかりとblocking処理がnon-blockingなthread上で実行されないように注意してください。 その場合は、subscribeOn/publishOnでblockしても良いExecutor/スレッドプールを引数に渡してください。
初見だとメソッドが多くて混乱しますが、IDE上でjavadocを眺めながら書けばあまり困ることはないと思います。 CompletableFutureよりも便利なメソッドが多いため、CompletableFutureと比較するとReactorのほうが書きやすいと思います。
CompletableFutureとの大きな違いとして、subscribe(block)するまでIO処理が実行されないことです。 同期的なプログラミング上でたまにやりがちなミスとしては、block()を呼び忘れていて、結果としてIO処理が実行されていなかったというパターンです。 結果が不要なケースで、この間違いをやりがちです。結果がいるときは、必然的にblock()を呼び出すので忘れないんですが...。
private fun addItem(item: Item) {
apiClient.addItem(item) // BAD
apiClient.addItem(item).block() // OK
}
Monoの作り方
基本的にはReactorに対応しているライブラリ側が作ってくれるので自分で書くケースは少ない、と思います。 が、blockingな処理(e.g. JDBC)を非同期化する時は自分で作る必要があるので、簡単にですが紹介しておきます。
Mono.fromCallableで、blockingな処理をwrapし、後続するsubscribeOnで実行するスレッドを指定すればいいです。
ref: https://projectreactor.io/docs/core/release/reference/#faq.wrap-blocking
fun getLoggedInUser(token: String): Mono<User> {
return Mono.fromCallable {
verifyToken(token)
}.subscribeOn(Schedulers.boundedElastic())
}
Reactorだと、Schedulers.boundedElastic()というblocking処理用のスレッドプールがあります。もちろん、自分で用意したExecutor/スレッドプールを使用することも可能です。 ただしあくまでスレッドプールを使って非同期化するだけなので、non-blocking IOと比較するとあまり効率はよくありません。(前述したように)
すでに値がある場合は、Mono.just("hoge")等で作ることができます。
Kotlin Coroutines (suspend function)
CompletableFutureやReactive StreamsによってJS Promiseライクには書けるようにはなりました。ですが、依然として書きやすいとは言えません。
Kotlin Coroutinesは、この問題を解決してくれます。JSにおけるasync/awaitのように、同期的なスタイルで書くことができます。違いは、suspend functionを使うだけです。 だいぶ書きやすいですね。
// Kotlin Coroutines対応しているWebフレームワークの場合は、コントローラーにsuspend functionが使える
suspend fun getFavoriteItems(request: HttpRequest): ResponseEntity<Any> {
val token = request.header("x-some-token")
return try {
val user = getLoggedInUser(token)
val favoriteItems = getFavoriteItems(user.userId)
ResponseEntity.ok(favoriteItems)
} catch (e: Exception) {
when (e) {
is AuthenticateException -> ResponseEntity.status(HttpStatus.UNAUTHORIZED).body("failed to authenticate")
else -> ResponseEntity.status(HttpStatus.INTERNAL_SERVER_ERROR).body("failed to get favorite items")
}
}
}
// suspend function
suspend fun getLoggedInUser(token: String): User {
// 省略
}
// suspend functionになる
suspend fun getFavoriteItems(userId: String): List<Item> {
// 省略
}
また、runBlocking {...} でwrapすることで現在のスレッド上でblockingした上で実行し結果を得ることもできるので、従来の同期的なプログラミングにおいても使うことができます。 つまり、IO処理をするクラス/メソッドはsuspend functionで実装しておけば、非同期/同期プログラミングの両方に使えるので便利です。
runBlocking {
// call suspend function
}
Completable Future, Reactorと同様ですが、blockingしてはいけないDispatcher上でblockingな処理を行ってはいけません。 その場合はwithContextでDispatcherを切り替えた上で実行してください。DefaultScheduler.IOなら、blockingな処理を行っても大丈夫です。
withContext(Dispatchers.IO) {
// exec blocking
}
また、Coroutinesの良い点として、スタックトレースをぶっ壊さないという点があります。(これまでの方法だと、別のスレッドで実行されるため、当然スタックトレースがちゃんと積み上がらない)
注意点ですが、Kotlin Coroutines = async/await ではありません。軽量スレッドとして、JavaでいうところのExecutorServiceのような用途で使うこともできます。
Kotlin Coroutinesについては、公式のドキュメントを一通り読むといいでしょう。
https://kotlinlang.org/docs/coroutines-overview.html#tutorials
非同期で注意/工夫すべきこと
non-blockingが求められる箇所で、blockingな処理をしないようにする
すでに何度か書いてきたように、non-blockingで書かないといけない場所で、うっかりblockingな処理をしないようにしてください。Intellij IDEAはけっこう賢いので、指摘してくれることもあります。 また、BlockHound というライブラリをいれるとそういったミスを実行時に検出してくれます。localやdev環境では、BlockHoundを適用しておくと便利でしょう。(たまに変なbugあるが...
Spring MVC等でreactorを使うときも注意してください。Spring MVCにおいてblockingしても大丈夫なのはrequest threadです。 reactorのmap/flatMap等のメソッドは、non-blockingなスレッド上で実行されることが多いので注意してください。
// Spring MVCにおいて
val user = getUser("userId") // Mono<user>
.map {
// ここでblockingなコードは書いてはダメ。
// 例えば、Monoの生成元がlettuceならlettuceのevent loop threadで実行されるので。同様にWebClient(WebFlux)の場合はreactor-nettyのevent loop threadで実行されるため。
}
.block() // これはOK
コンテキストの伝搬を意識する
ここでいうコンテキストとは、requestの情報や、MDC, zipkinのTraceContextのようなものだと思ってください。
従来のJavaにおいては、コンテキストはThreadLocal(スレッドごとに使えるグローバル変数のようなもの)に保持するというパターンが大半を占めていました。
- 例えば、
- Spring MVCにおけるRequestContextHolderはThreadLocalを使って実装されている
- MDCはThreadLocalを使って実装されている
- ZipkinのCurrentTraceContextもデフォルトはThreadLocalを使って実装されている。
同一のrequest thread上で処理を実行していくSpring MVCでは、この方法でなんら問題はありません。
しかし、non-blockingなWebフレームワークではこの問題では影響がでます。このwikiの最初のほうで說明したように、event loopスレッド上で複数のリクエストをハンドリング(= 1つのリクエストの処理が完了するまで同期的にスレッドを専有しない)するので、ThreadLocalを使った手法では問題が発生します。
そこで、多くのnon-blockingなWebフレームワークでは、"Context"という仕組みが別途用意されていて、ThreadLocalの代わりにそれを使います。 簡単にいうと、MapのようなContextオブジェクトを連続する処理で引き回していく、みたいな感じです。
※ コンテキストの伝搬に関しては後日また別途記事を書きます。今回は簡単な紹介のみにとどめます。
Spring WebFluxの場合
ReactorのContextを利用します。
例えば、こんな感じです。contextWriteメソッドによりContextにセットした値を、upstream operator上(flatMap)で参照することができます。 Context自体は、Mapのように利用することができます。
@GetMapping("/test/contextSample")
fun contextSample(): Mono<Int> {
val userId = "xxx"
return Mono.just(1)
.flatMap { data ->
Mono.deferContextual { ctx ->
log.info("userId={}", ctx.get("userId"))
Mono.just(data)
}
}
.contextWrite { ctx -> ctx.put("userId", userId) }
}
実際は、WebFilterを使ってRequest情報やzipkinのTraceContextをContextにいれておく、といったパターンが多いと思います。
Armeriaの場合
ArmeriaのRequestContextを使用します。
例えば、こんな感じです。
@Get("/hello")
fun hello(ctx: ServiceRequestContext): HttpResponse {
val userId = "xxx"
ctx.setAttr(AttributeKey.valueOf("userId"), userId)
someOperation()
return HttpResponse.of("Hello")
}
private fun someOperation() {
val ctx = RequestContext.current<ServiceRequestContext>()
log.info("userId={}", ctx.attr(AttributeKey.valueOf<String>("userId")))
}
Armeriaは、event loopスレッドで処理をするときにRequestContextをThreadLocalにrestore/resetをしているので、RequestContext.currentで取得することもできます。
ただし、これで取得できるのはあくまでarmeriaのevent loop thread上のみ可能なので注意してください。
https://github.com/line/armeria/blob/master/core/src/main/java/com/linecorp/armeria/internal/common/RequestContextUtil.java#L220-L237
おわりに
歴史から振り返ってみたことで、以下のような点がなんとなくクリアになったと思います。(なってたら幸いです
- なんで非同期? non-blockingってなに?
- non-blockingなWebフレームワークだとthreadをblockしてはいけないって聞くけど、なんで?
- FutureとかCompletableFutureとかReactorとか色々あるけど、なんで? なにが違うの?
- Contextをごちゃごちゃする小難しいコードがあるけど、なんで必要なの?